对象在堆上是如何存储的?
对象在堆上是如何存储的?
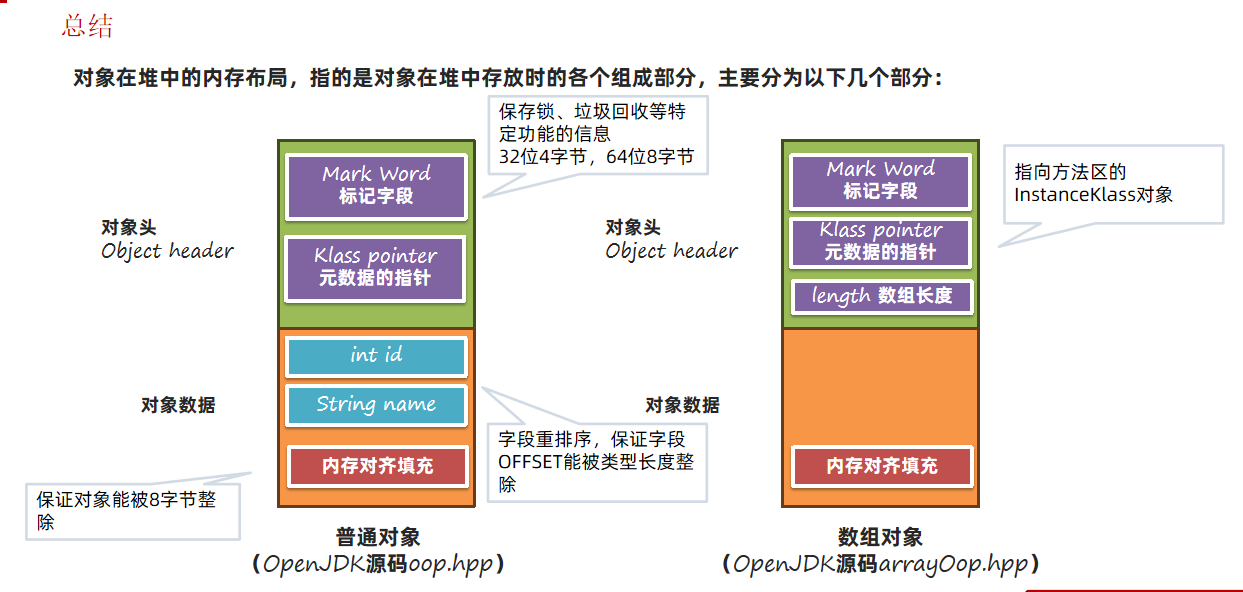
对象在堆中的内存布局,指的是对象在堆中存放时的各个组成部分,主要分为以下几个部分:
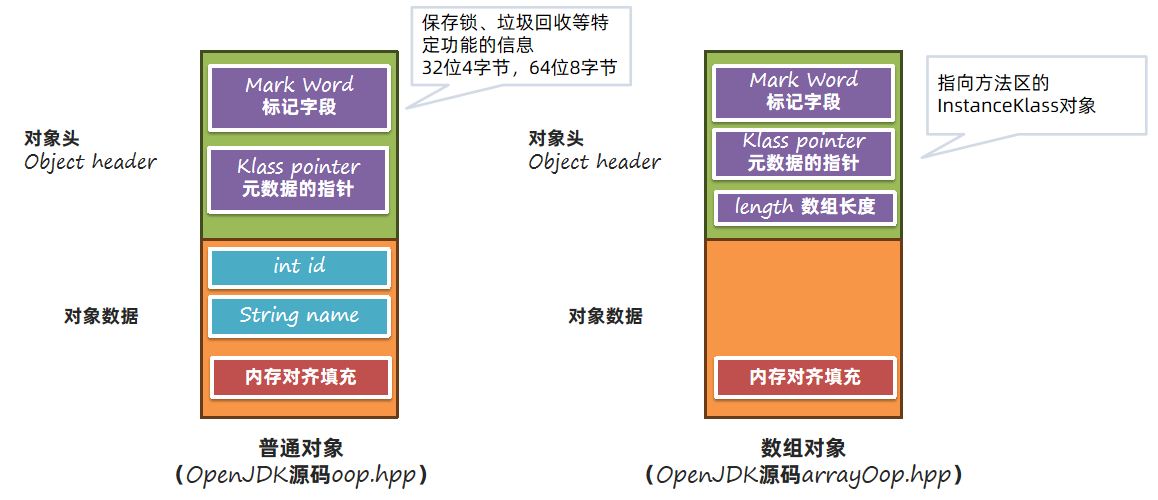
# 标记字段
标记字段相对比较复杂。在不同的对象状态(有无锁、是否处于垃圾回收的标记中)下存放的内容是不同的,同时在64位(又分为是否开启指针压缩)、32位虚拟机中的布局都不同。以64位开启指针压缩为例:

怎么确认标记字段的内容呢?我们可以使用JOL,JOL是用于分析 JVM 中对象布局的一款专业工具。工具中使用 Unsafe、JVMTI 和 Serviceability Agent (SA)等虚拟机技术来打印实际的对象内存布局。
使用方法:
1、添加依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
2、使用如下代码打印对象内存布局:
System.out.println(ClassLayout.parseInstance(对象).toPrintable());
代码:
package oop1;
import org.openjdk.jol.info.ClassLayout;
import java.io.IOException;
//-XX:-UseCompressedOops 关闭压缩指针
public class Student {
private long id;
private int age;
private String name;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public static void main(String[] args) throws IOException {
Student student = new Student();
System.out.println(Integer.toBinaryString(student.hashCode()));
System.out.println(ClassLayout.parseInstance(student).toPrintable());
System.in.read();
}
}
//0010011 01011111 10111010 10100100
// 0x26163608
打印结果如下:
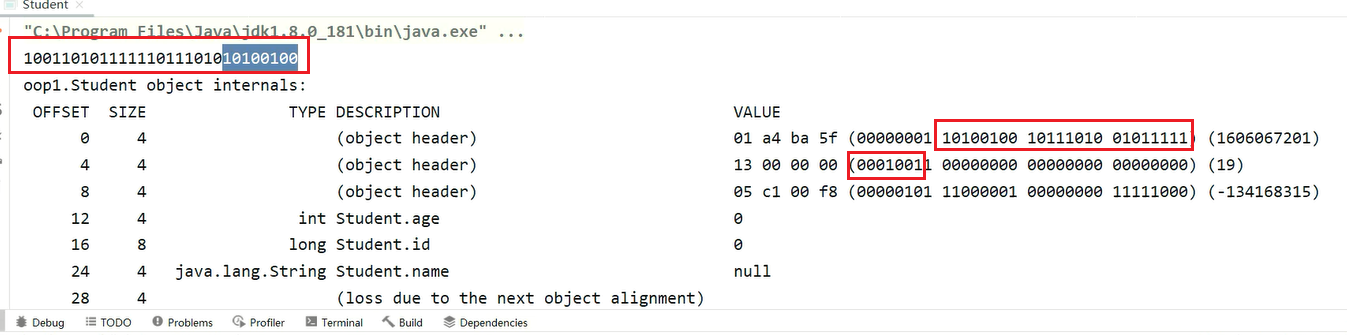
和hashcode值是一致的(注意小端存储,结果会倒着写)


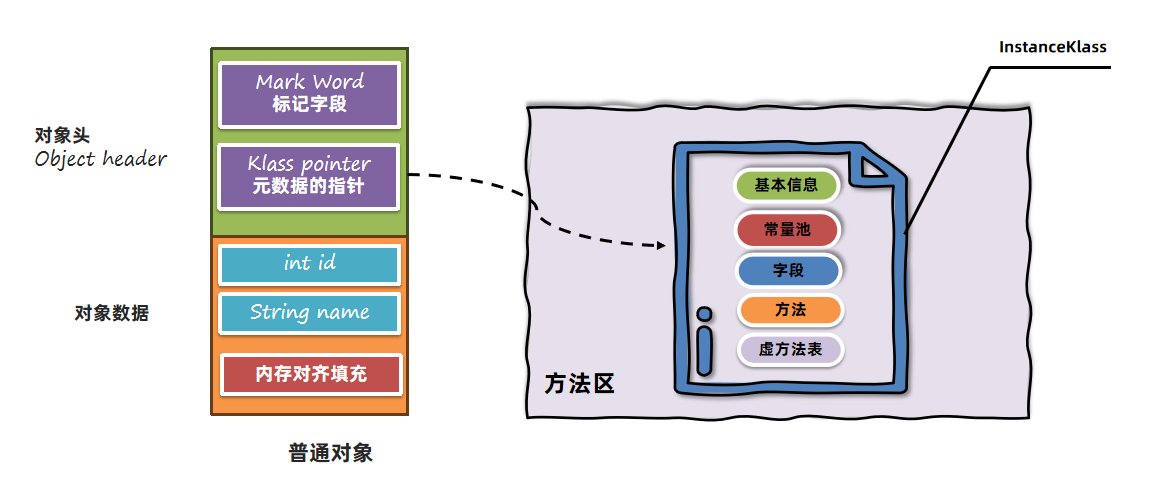
# 元数据的指针
Klass pointer元数据的指针指向方法区中保存的InstanceKlass对象:
# 指针压缩
在64位的Java虚拟机中,Klass Pointer以及对象数据中的对象引用都需要占用8个字节,为了减少这部分的内存使用量,64 位 Java 虚拟机使用指针压缩技术,将堆中原本 8个字节的 指针压缩成 4个字节 ,此功能默认开启,可以使用-XX:-UseCompressedOops关闭。
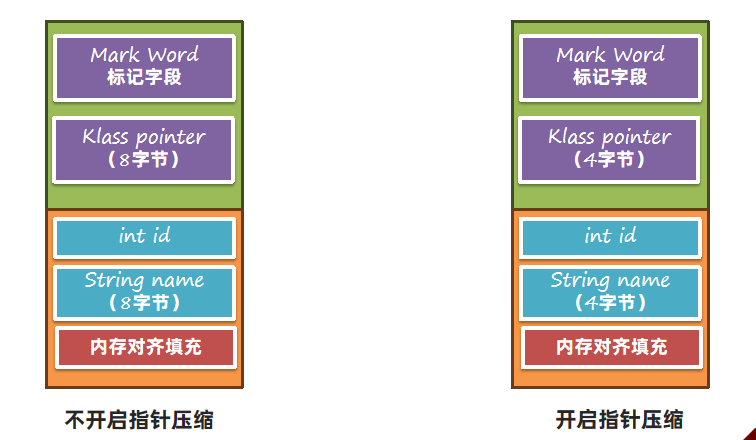
指针压缩的思想是将寻址的单位放大,比如原来按1字节去寻址,现在可以按8字节寻址。如下图所示,原来按1去寻址,能拿到1字节开始的数据,现在按1去寻址,就可以拿到8个字节开始的数据。
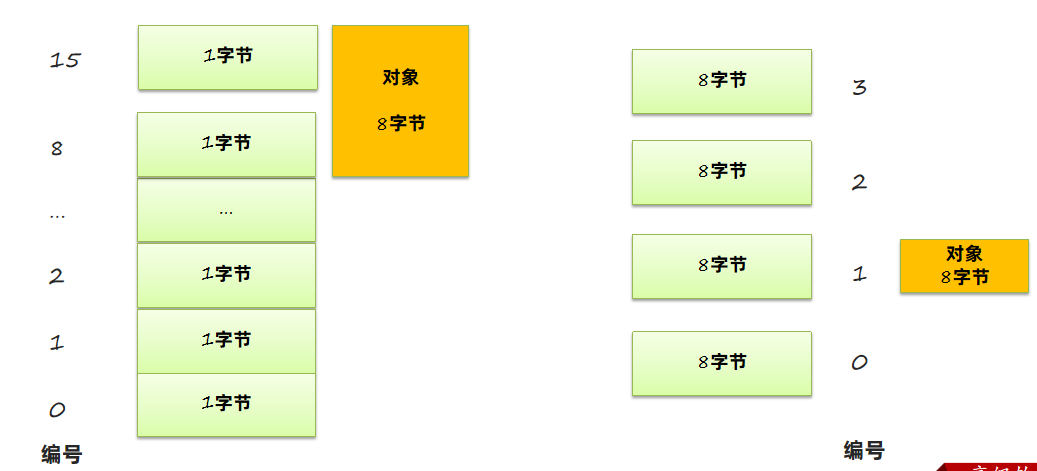
这与停车场是类似的。以前需要记录我的车占用了那几米的空间,现在只需要记下停车场的编号:

这样将编号当成地址,就可以用更小的内存访问更多的数据。但是这样的做法有两个问题:
1、需要进行内存对齐,指的是将对象的内存占用填充至8字节的倍数。存在空间浪费(对于Hotspot来说不存在,即便不开启指针压缩,也需要进行内存对齐)

2、寻址大小仅仅能支持2的35 次方个字节(32GB,如果超过32GB指针压缩会自动关闭)。不用压缩指针,应该是2的64次方 = 16EB,用了压缩指针就变成了8(字节) = 2的3次方 * 2的32次方 = 2的35次方

# 案例:在hsdb工具中验证klass pointer正确性
操作步骤:
1、使用JOL打印对象的Klass Pointer。
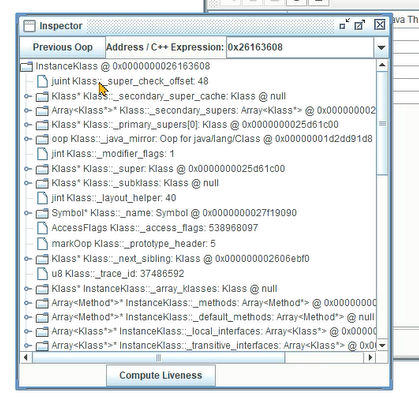
2、使用Klass Pointer的地址,在hsdb工具中使用Inspector找到InstanceKlass对象。
注意:由于使用了小端存储,打印的地址要反着读。
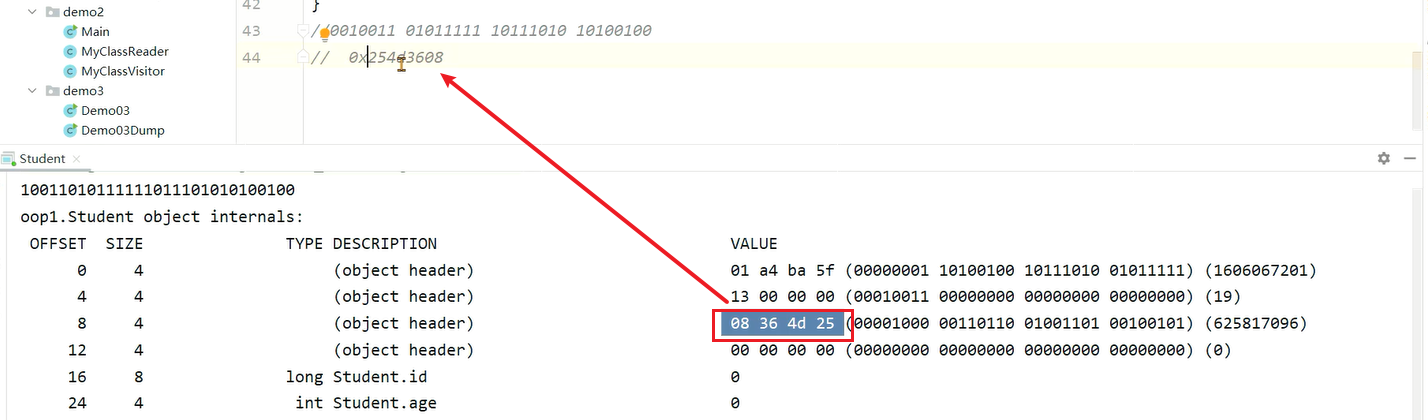
这个0x254d3608就是klass对象的地址:
# 内存对齐
对象中还有一部分内容就是对齐。内存对齐指的是对象中会空出来几个字节,不做任何数据存储。内存对齐主要目的是为了解决并发情况下CPU缓存失效的问题:
在内存中缓存了A和B的数据

A的数据写入时,由于A和B在同一个缓存行中,所以A和B的缓存数据都会被清空:
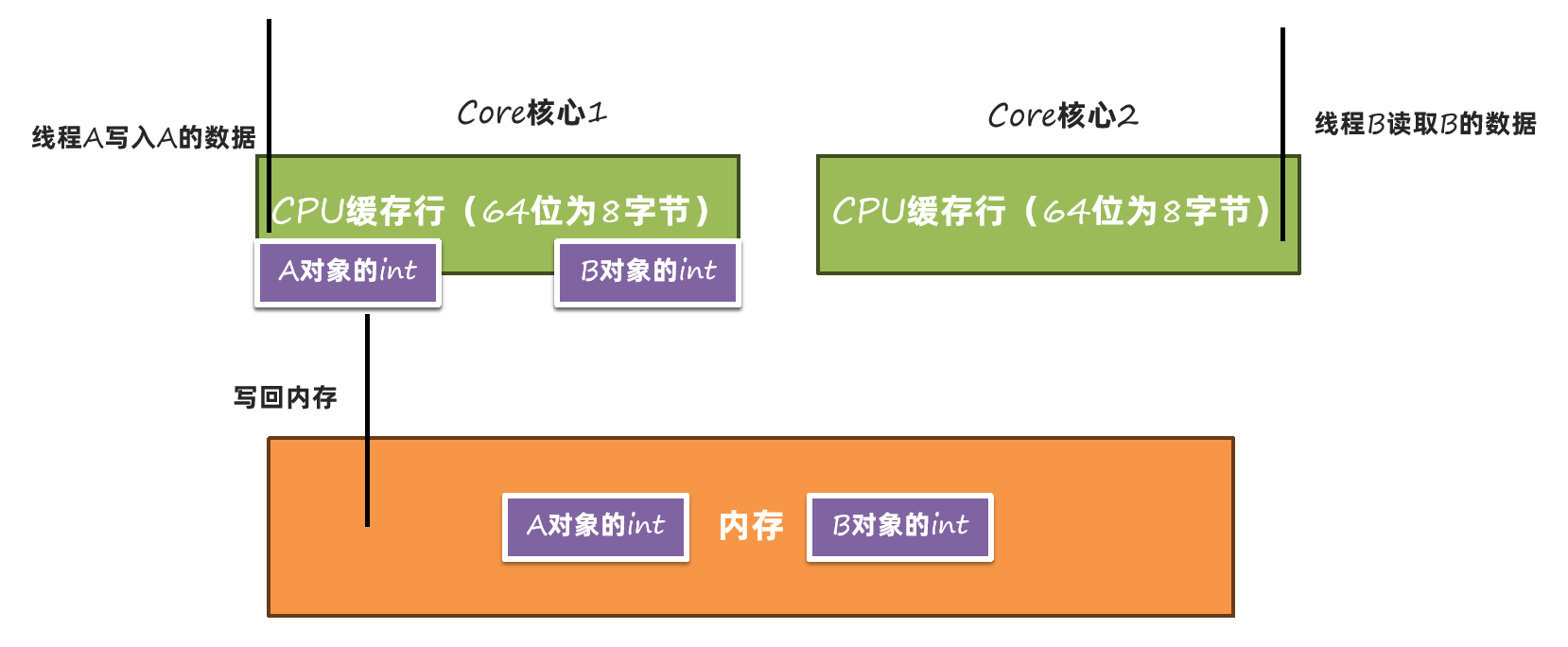
这样就需要再从内存中读取一次:
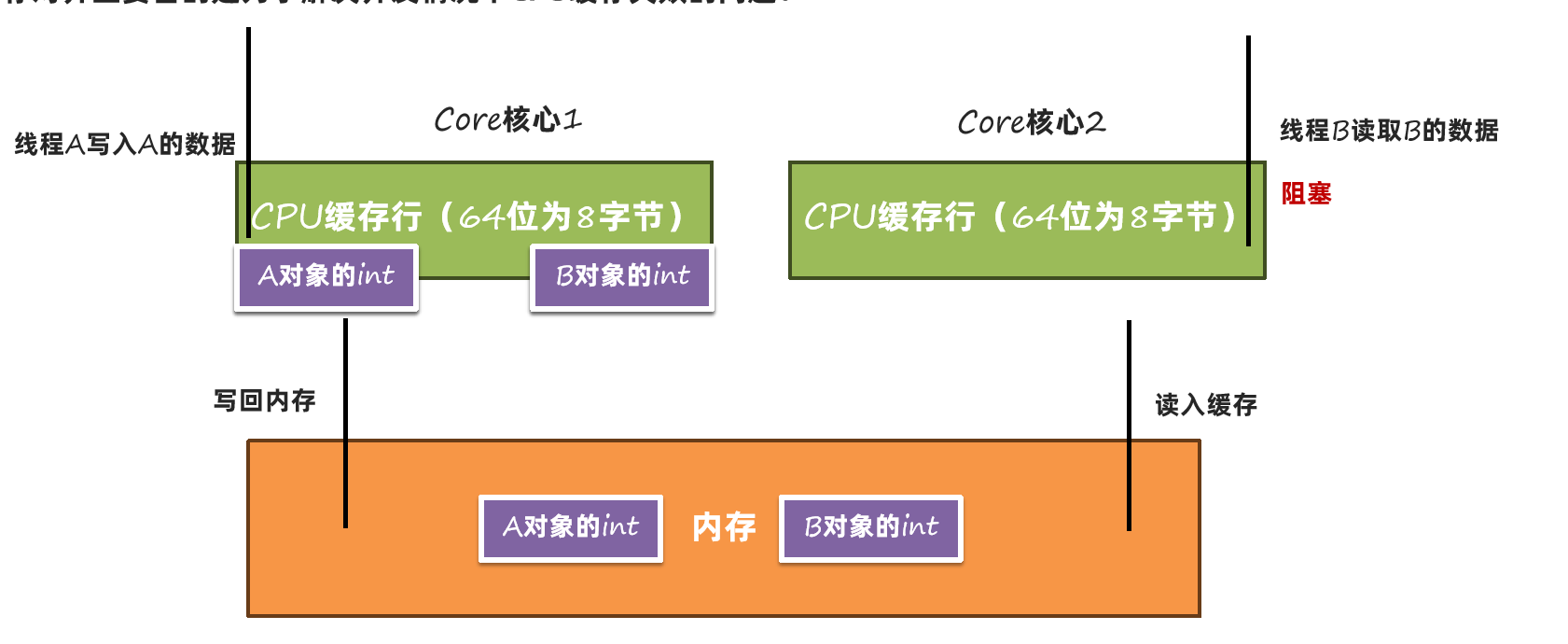
我们只修改了A对象的数据,引起了B对象的缓存失效。
内存对齐解决了这个问题:内存对齐之后,同一个缓存行中不会出现不同对象的属性。在并发情况下,如果让A对象一个缓存行失效,是不会影响到B对象的缓存行的。
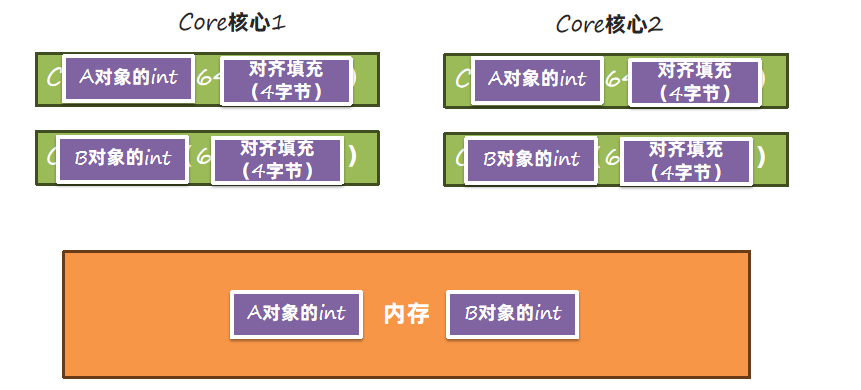
内存对齐要求每个对象字节数是8的倍数,除了添加字节填充之外,还有字段的要求。
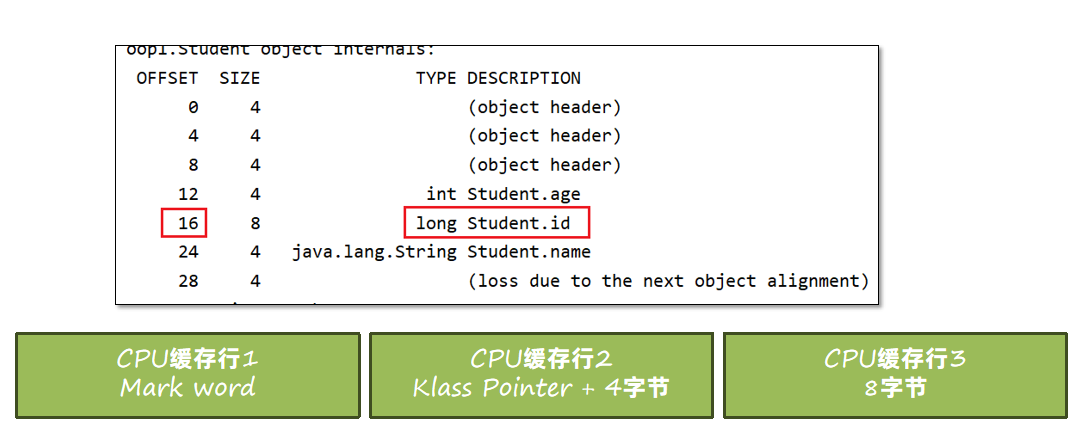
在Hotspot中,要求每个属性的偏移量Offset(字段地址 – 起始地址)必须是字段长度的N倍。
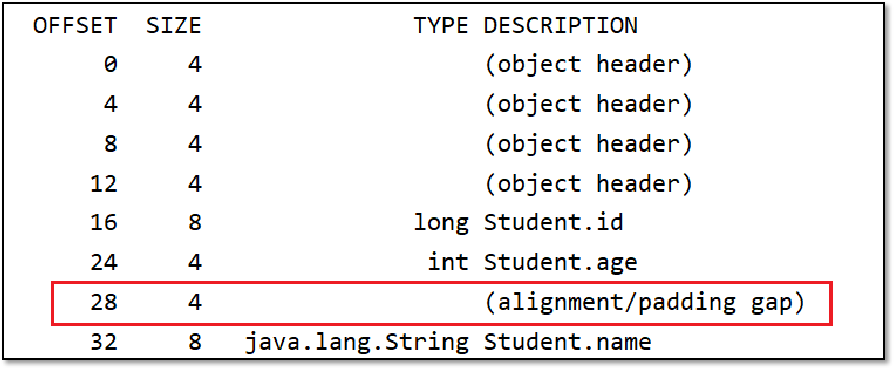
比如下图中,Student类中的id属性类型为long,那么偏移量就必须是8的倍数。所以将id和age的字段顺序进行了调整,这种方式叫字段重排列。
这样可以更容易让一个字段在一整个缓存行中,提升缓存行读取的效率。
如果不满足要求,会尝试使用内存对齐,通过在属性之间插入一块对齐区域达到目的。
如下图中,name字段是引用占用8个字节(关闭了指针压缩),所以Offset必须是8的倍数,在age和name之间插入了4个字节的空白区域。
# 案例:子类和父类的偏移量
需求:
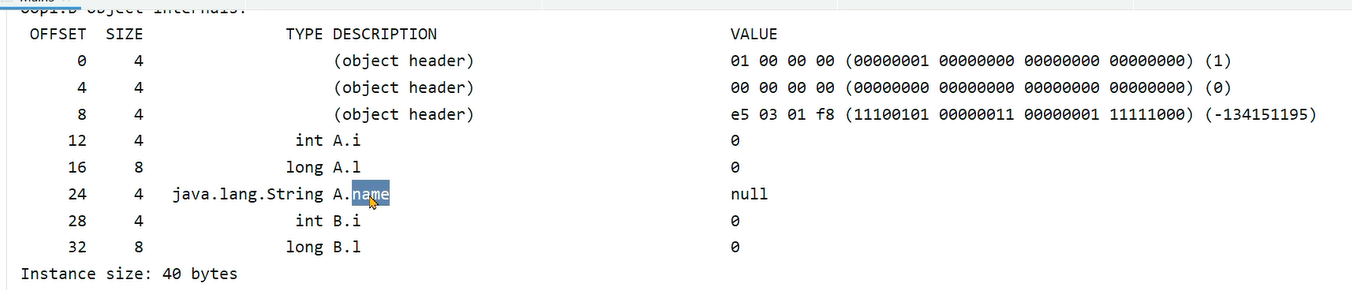
通过如下代码验证下:子类继承自父类的属性,属性的偏移量和父类是一致的。
package oop1;
class A {
long l;
int i;
String name;
}
class B extends A {
long l;
int i;
}
class C{
long l1;
int i1;
String name;
long l2;
int i2;
}
结果如下:
总结: