 JIT即时编译器
JIT即时编译器
在Java中,JIT即时编译器是一项用来提升应用程序代码执行效率的技术。字节码指令被 Java 虚拟机解释执行,如果有一些指令执行频率高,称之为热点代码,这些字节码指令则被JIT即时编译器编译成机器码同时进行一些优化,最后保存在内存中,将来执行时直接读取就可以运行在计算机硬件上了。

在HotSpot中,有三款即时编译器,C1、C2和Graal,其中Graal在GraalVM章节中已经介绍过。
C1编译效率比C2快,但是优化效果不如C2。所以C1适合优化一些执行时间较短的代码,C2适合优化服务端程序中长期执行的代码。
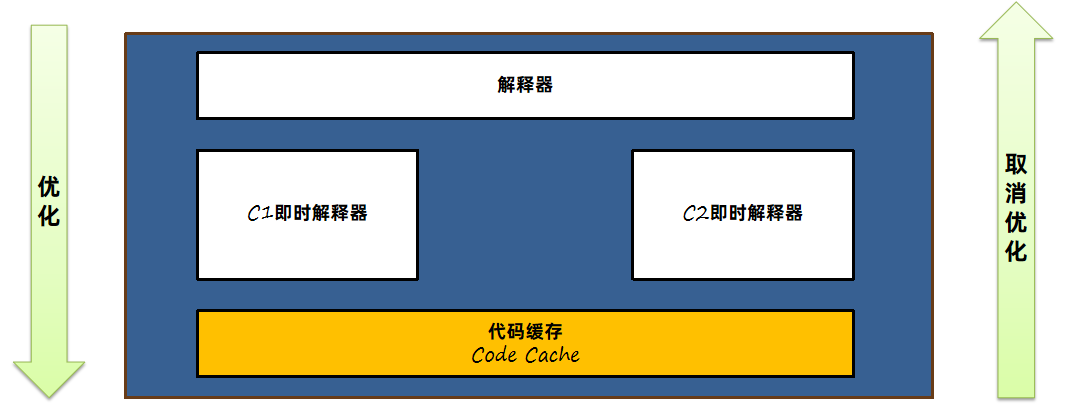
JDK7之后,采用了分层编译的方式,在JVM中C1和C2会一同发挥作用,分层编译将整个优化级别分成了5个等级。
| 等级 | 使用的组件 | 描述 | 保存的内容 | 性能打分(1 - 5) |
|---|---|---|---|---|
| 0 | 解释器 | 解释执行记录方法调用次数及循环次数 | 无 | 1 |
| 1 | C1即时编译器 | C1完整优化 | 优化后的机器码 | 4 |
| 2 | C1即时编译器 | C1完整优化记录方法调用次数及循环次数 | 优化后的机器码部分额外信息:方法调用次数及循环次数 | 3 |
| 3 | C1即时编译器 | C1完整优化记录所有额外信息 | 优化后的机器码所有额外信息:分支跳转次数、类型转换等等 | 2 |
| 4 | C2即时编译器 | C2完整优化 | 优化后的机器码 | 5 |
C1即时编译器和C2即时编译器都有独立的线程去进行处理,内部会保存一个队列,队列中存放需要编译的任务。一般即时编译器是针对方法级别来进行优化的,当然也有对循环进行优化的设计。
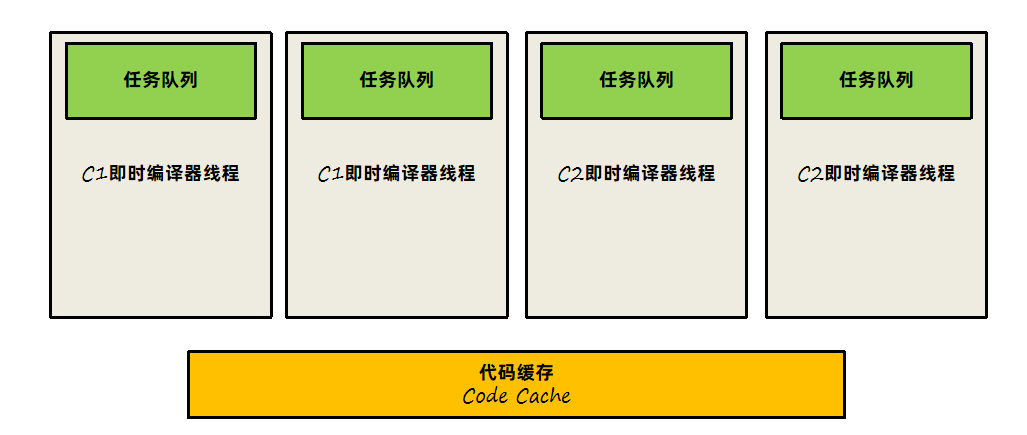
详细来看看C1和C2是如何进行协作的:
1、先由C1执行过程中收集所有运行中的信息,方法执行次数、循环执行次数、分支执行次数等等,然后等待执行次数触发阈值(分层即时编译由JVM动态计算)之后,进入C2即时编译器进行深层次的优化。

2、方法字节码执行数目过少,先收集信息,JVM判断C1和C2优化性能差不多,那之后转为不收集信息,由C1直接进行优化。

3、C1线程都在忙碌的情况下,直接由C2进行优化。

4、C2线程忙碌时,先由2层C1编译收集一些基础信息,多运行一会儿,然后再交由3层C1处理,由于3层C1处理效率不高,所以尽量减少这一层停留时间(C2忙碌着,一直收集也没有意义),最后C2线程不忙碌了再交由C2进行处理。

# 案例:测试JIT即时编译器的优化效果
需求:
1、编写JMH案例,代码如下:
/*
* Copyright (c) 2005, 2014, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
package org.sample;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
//执行5轮预热,每次持续1秒
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
//执行一次测试
@Fork(value = 1, jvmArgsAppend = {"-Xms1g", "-Xmx1g"})
//显示平均时间,单位纳秒
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class MyJITBenchmark {
public int add (int a,int b){
return a + b;
}
public int jitTest(){
int sum = 0;
for (int i = 0; i < 10000000; i++) {
sum = add(sum,100);
}
return sum;
}
//禁用JIT
@Benchmark
@Fork(value = 1,jvmArgsAppend = {"-Xint"})
public void testNoJIT(Blackhole blackhole) {
int i = jitTest();
blackhole.consume(i);
}
//只使用C1 1层
@Benchmark
@Fork(value = 1,jvmArgsAppend = {"-XX:TieredStopAtLevel=1"})
public void testC1(Blackhole blackhole) {
int i = jitTest();
blackhole.consume(i);
}
//分层编译
@Benchmark
public void testMethod(Blackhole blackhole) {
int i = jitTest();
blackhole.consume(i);
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(MyJITBenchmark.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}
2、分别采用三种不同虚拟机参数测试JIT优化效果:不加参数(开启完全JIT即时编译),-Xint(关闭JIT只使用解释器)、-XX:TieredStopAtLevel=1(分层编译下只使用1层C1进行编译)
测试结果如下:

JIT编译器主要优化手段是方法内联和逃逸分析。
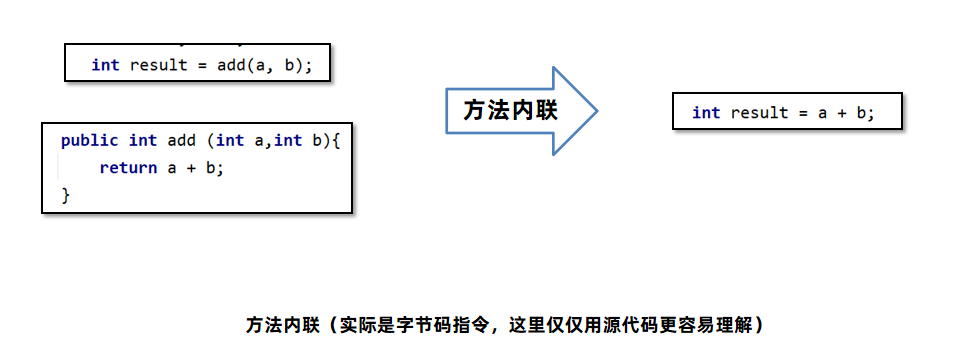
# 方法内联
方法内联(Method Inline):方法体中的字节码指令直接复制到调用方的字节码指令中,节省了创建栈帧的开销。
需求: 1、安装JIT Watch工具,下载源码:https://github.com/AdoptOpenJDK/jitwatch/tree/1.4.2 2、使用资料中提供的脚本文件直接启动。
3、添加源代码目录,点击沙箱环境RUN:
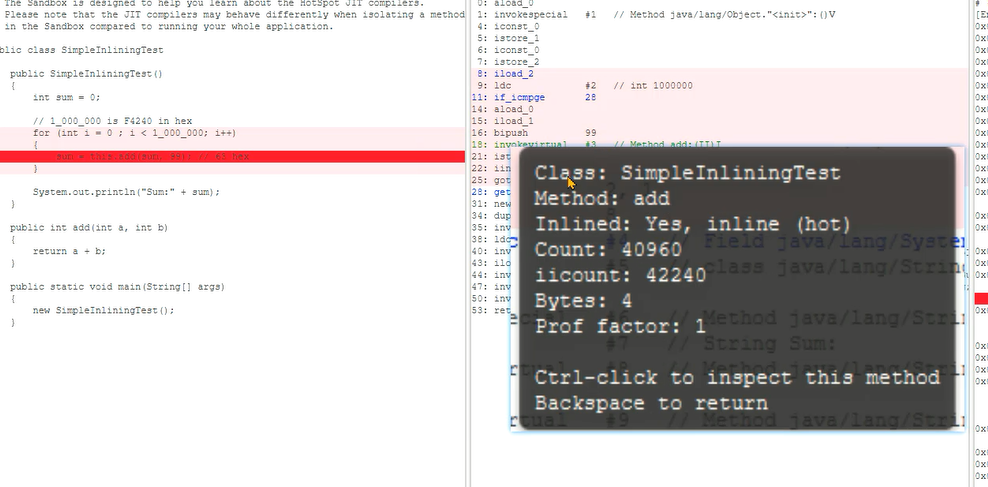
4、通过JIT Watch观察到通过C1调用多次收集信息之后,进入C2优化。C2优化之后的机器码大小非常小。

5、方法调用进行了内联优化,汇编代码中直接使用乘法计算出值再进行累加,这样效率更高。
并不是所有的方法都可以内联,内联有一定的限制:
1、方法编译之后的字节码指令总大小 < 35字节,可以直接内联。(通过-XX:MaxInlineSize=值 控制)
2、方法编译之后的字节码指令总大小 < 325字节,并且是一个热方法。(通过-XX:FreqInlineSize=值 控制)
3、方法编译生成的机器码不能大于1000字节。(通过-XX:InlineSmallCode=值 控制)
4、一个接口的实现必须小于3个,如果大于三个就不会发生内联。
# 案例:String的toUpperCase方法性能优化
需求:
1、String的toUpperCase为了适配很多种不同的语言导致方法编译出来的字节码特别大,通过编写一个方法只处理a-z的大写转换提升性能。
2、通过JIT Watch观察方法内联的情况。
import java.util.Locale;
public class UpperCase
{
public String upper;
public UpperCase()
{
int iterations = 10_000_000;
String source = "Lorem ipsum dolor sit amet, sensibus partiendo eam at.";
long start = System.currentTimeMillis();
convertString(source, iterations);
System.out.println(upper);
System.out.println(System.currentTimeMillis() - start);
start = System.currentTimeMillis();
convertCustom(source, iterations);
System.out.println(upper);
System.out.println(System.currentTimeMillis() - start);
}
private void convertString(String source, int iterations)
{
for (int i = 0; i < iterations; i++)
{
upper = source.toUpperCase(Locale.getDefault());
}
}
private void convertCustom(String source, int iterations)
{
for (int i = 0; i < iterations; i++)
{
upper = doUpper(source);
}
}
private String doUpper(String source)
{
StringBuilder builder = new StringBuilder();
int len = source.length();
for (int i = 0; i < len; i++)
{
char c = source.charAt(i);
if (c >= 'a' && c <= 'z')
{
c -= 32;
}
builder.append(c);
}
return builder.toString();
}
public static void main(String[] args)
{
new UpperCase();
}
}
3、通过JIT测试性能:
import java.util.Locale;
public class UpperCase
{
public String upper;
public UpperCase()
{
int iterations = 10_000_000;
String source = "Lorem ipsum dolor sit amet, sensibus partiendo eam at.";
long start = System.currentTimeMillis();
convertString(source, iterations);
System.out.println(upper);
System.out.println(System.currentTimeMillis() - start);
start = System.currentTimeMillis();
convertCustom(source, iterations);
System.out.println(upper);
System.out.println(System.currentTimeMillis() - start);
}
private void convertString(String source, int iterations)
{
for (int i = 0; i < iterations; i++)
{
upper = source.toUpperCase(Locale.getDefault());
}
}
private void convertCustom(String source, int iterations)
{
for (int i = 0; i < iterations; i++)
{
upper = doUpper(source);
}
}
private String doUpper(String source)
{
StringBuilder builder = new StringBuilder();
int len = source.length();
for (int i = 0; i < len; i++)
{
char c = source.charAt(i);
if (c >= 'a' && c <= 'z')
{
c -= 32;
}
builder.append(c);
}
return builder.toString();
}
public static void main(String[] args)
{
new UpperCase();
}
}
最终结果:

自行实现的方法性能要比JDK默认提供的高很多,当然只支持对a-z做大写化。
# 逃逸分析
逃逸分析指的是如果JIT发现在方法内创建的对象不会被外部引用,那么就可以采用锁消除、标量替换等方式进行优化。
这段代码可以使用逃逸分析进行优化,因为test对象不会被外部引用,只会在方法中使用。
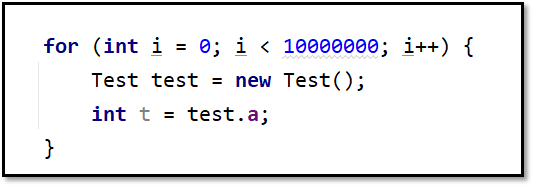
这段代码就会有一定的问题,如果在方法中对象被其他静态变量引用,那优化就无法进行。

# 锁消除
逃逸分析中的锁消除指的是如果对象被判断不会逃逸出去,那么在对象就不存在并发访问问题,对象上的锁处理都不会执行,从而提高性能。比如如下写法

锁消除优化在真正的工作代码中并不常见,一般加锁的对象都是支持多线程去访问的。
# 标量替换
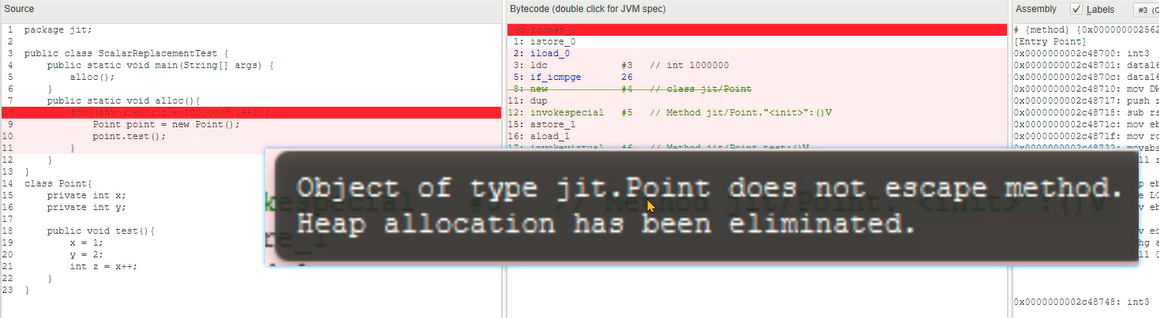
逃逸分析真正对性能优化比较大的方式是标量替换,在Java虚拟机中,对象中的基本数据类型称为标量,引用的其他对象称为聚合量。标量替换指的是如果方法中的对象不会逃逸,那么其中的标量就可以直接在栈上分配。
如下图中,point对象不存在逃逸,那么就可以将test方法中的字节码指令直接挪到循环中,减少方法调用的开销。

性能测试
需求:
1、编写JMH性能测试案例,测试方法内联和标量替换之后的性能变化。
2、分别使用三种不同虚拟机参数进行测试:
- 开启方法内联和标量替换
- 关闭标量替换
- 关闭所有优化
3、比对测试结果。
/*
* Copyright (c) 2005, 2014, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
package org.sample;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.Random;
import java.util.concurrent.TimeUnit;
//执行5轮预热,每次持续1秒
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
//执行一次测试
//显示平均时间,单位纳秒
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Measurement(iterations = 3,time = 1,timeUnit = TimeUnit.SECONDS)
@State(Scope.Benchmark)
public class EscapeAnalysisBenchmark2 {
public int test(){
int count = 0;
for (int i = 0; i < 10000000; i++) {
Point point = new Point();
point.test();
}
return count;
}
@Benchmark
@Fork(value = 1,jvmArgsAppend = {"-Xmx10m"})
public void testWithJIT(Blackhole blackhole) {
int i = test();
blackhole.consume(i);
}
@Benchmark
@Fork(value = 1,jvmArgsAppend = {"-XX:-DoEscapeAnalysis","-Xmx10m"})
public void testWithoutEA(Blackhole blackhole) {
int i = test();
blackhole.consume(i);
}
@Benchmark
@Fork(value = 1,jvmArgsAppend = {"-Xint","-Xmx10m"})
public void testWithoutJIT(Blackhole blackhole) {
int i = test();
blackhole.consume(i);
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(EscapeAnalysisBenchmark2.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}
class Point{
private int x;
private int y;
public void test(){
x = 1;
y = 2;
int z = x++;
}
}
测试结果:

性能最高的是JIT功能全开的情况下;不开启逃逸分析,虽然方法内联还生效,但是性能要差很多;完全不开性能就特别差了。
# 案例:使用JIT Watch工具查看逃逸分析的优化结果需求:
1、在JIT Watch中创建新的文件,将之前准备好的代码复制进去。
2、观察创建对象这一行源代码的字节码信息。
3、对象没有逃离方法的作用域,可以标量替换等方式进行优化。
# 总结
根据JIT即时编器优化代码的特性,在编写代码时注意以下几个事项,可以让代码执行时拥有更好的性能:
1、尽量编写比较小的方法,让方法内联可以生效。
2、高频使用的代码,特别是第三方依赖库甚至是JDK中的,如果内容过度复杂是无法内联的,可以自行实现一个特定的优化版本。
3、注意下接口的实现数量,尽量不要超过2个,否则会影响内联的处理。
4、高频调用的方法中创建对象临时使用,尽量不要让对象逃逸。